
Transformer models are used to solve all kinds of NLP tasks. Transformers are a revolutionary architecture in the field of Natural Language Processing (NLP) that have significantly advanced the state-of-the-art in various NLP tasks. Before delving into Transformer models, let’s take a moment to understand the basics of natural language processing (NLP) and its significance.
NLP
Natural Language Processing (NLP) is all about language and machines working together to understand human communication better. It’s not just about knowing what individual words mean, but understanding how they fit together in sentences and conversations.
Here are some common NLP tasks, along with examples for each:
- Sentence Classification: Understanding the sentiment of a movie review, deciding if an email is spam or not, checking if a sentence is grammatically correct, or figuring out if two sentences are related.
- Word Classification: Identifying the parts of speech in a sentence (like nouns, verbs, or adjectives), or recognizing named entities (such as names of people, places, or organizations).
- Text Generation: Writing new text based on a given prompt, or filling in missing words in a sentence.
- Answer Extraction From Text: Finding the answer to a question by looking through a passage of text.
- Sentence Generation: Translating text from one language to another, or creating a summary of a longer text.
Transformer Models
The Transformers library from HuggingFace platform provides the functionality to create and use shared models. The Model Hub contains thousands of pretrained models that anyone can download and use. You can also upload your own models to the Hub.
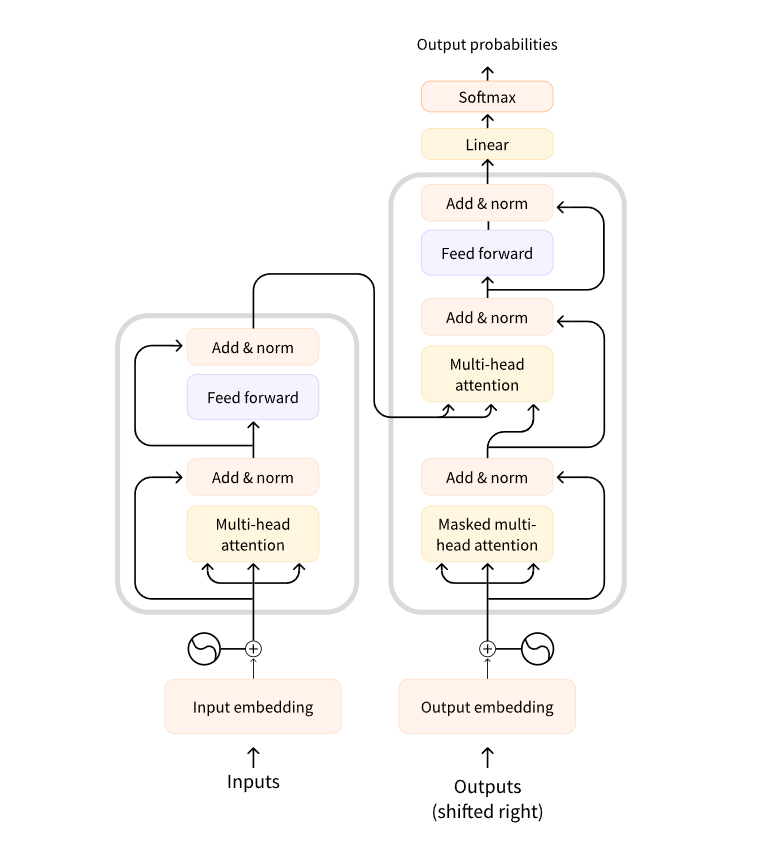
Let’s look at a few examples of transformer models and how they can be used to solve some interesting NLP problems. Before that lets look at the original Transformer architecture with the encoder on the left and the decoder on the right.
Working with pipelines
In the Transformers library, the pipeline() function is the simplest tool. It links a model with the steps needed to prepare and handle the text. So, you can just give it some text, and it will give you a clear answer. For this article i have implemented the codes in google colab, you can do the same.
Sentiment analysis using pipeline:
Install the Transformers, Datasets, and Evaluate libraries to run code.
!pip install datasets evaluate transformers[sentencepiece]from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a NLP course my whole life.")Output is:
[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
We can even pass several sentences!
classifier(
["I've been waiting for a NLP course my whole life.", "I hate this so much!"]
)Output is:
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
By default, this pipeline uses a specific pre-trained model that’s been adjusted to analyze sentiments in English. When you create the classifier, it downloads and saves the model. If you run the command again, it will use the saved model instead of downloading it again.
When you give some text to a pipeline, there are three main things that happen:
- The text gets ready for the model to use by pre-processing.
- The pre-processed text goes into the model.
- The model’s predictions are made easier to understand through post-processing.
Zero-shot classification using pipeline:
With this, you can choose which categories to use for classification, so you’re not stuck with the categories from the pre-trained model. You’ve seen how the model can say if a sentence is positive or negative using those two categories. But you can also use any other categories you want for classification.
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)Output is:
{'sequence': 'This is a course about the Transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
This pipeline is called zero-shot because you don’t need to fine-tune the model on your data to use it. It can directly return probability scores for any list of labels you want.
Text generation using pipeline:
Now, let’s learn how to use a pipeline to create some text. Basically, you give the model a starting point (a prompt), and it fills in the rest of the text for you. It’s like the predictive text feature you find on many phones. Because text generation involves some randomness, you might not always get the exact same results as shown below.
from transformers import pipeline
generator = pipeline("text-generation")
generator("In this course, we will teach you how to")Output is:
[{'generated_text': 'In this course, we will teach you how to understand and use '
'data flow and data interchange when handling user data. We '
'will be working with one or more of the most commonly used '
'data flows — data flows of various types, as seen by the '
'HTTP'}]
You can control how many different sequences are generated with the argument num_return_sequences and the total length of the output text with the argument max_length. Let’s try the distilgpt2 model! Here’s how to load it in the same pipeline as before:
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)Output is:
[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
'move your mental and physical capabilities to your advantage.'},
{'generated_text': 'In this course, we will teach you how to become an expert and '
'practice realtime,and with a hands on experience on both real '
'time and real'}]
Mask filling using pipeline:
The next pipeline you’ll try is fill-mask. The idea of this task is to fill in the blanks in a given text:
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about <mask> models.", top_k=2)Output is:
[{'sequence': 'This course will teach you all about mathematical models.',
'score': 0.19619831442832947,
'token': 30412,
'token_str': ' mathematical'},
{'sequence': 'This course will teach you all about computational models.',
'score': 0.04052725434303284,
'token': 38163,
'token_str': ' computational'}]
The top_k argument controls how many possibilities you want to be displayed. Note that here the model fills in the special word, which is often referred to as a mask token.
Named entity recognition using pipeline:
Named entity recognition (NER) is a task where the model has to find which parts of the input text correspond to entities such as persons, locations, or organizations.
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")Output is:
[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
]
Here the model correctly identified that Sylvain is a person (PER), Hugging Face an organization (ORG), and Brooklyn a location (LOC).
Question answering using pipeline:
The question-answering pipeline answers questions using information from a given context:
from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)Output is:
{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
Note that this pipeline works by extracting information from the provided context; it does not generate the answer.
Summarization using pipeline:
Summarization is the task of reducing a text into a shorter text while keeping all (or most) of the important aspects referenced in the text.
from transformers import pipeline
summarizer = pipeline("summarization")
summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)Output is:
[{'summary_text': ' America has changed dramatically during recent years . The '
'number of engineering graduates in the U.S. has declined in '
'traditional engineering disciplines such as mechanical, civil '
', electrical, chemical, and aeronautical engineering . Rapidly '
'developing economies such as China and India, as well as other '
'industrial countries in Europe and Asia, continue to encourage '
'and advance engineering .'}]
Translation using pipeline:
For translation, you can use a default model if you provide a language pair in the task name (such as “translation_en_to_fr”), but the easiest way is to pick the model you want to use on the HuggingFace Model Hub.
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
translator("Ce cours est produit par Hugging Face.")Output is:
[{'translation_text': 'This course is produced by Hugging Face.'}]
Like with text generation and summarization, you can specify a max_length or a min_length for the result.
In this article, you saw how to approach different NLP tasks using the high-level pipeline() function from Transformers.