
Machine learning is a subset of artificial intelligence that tells us about the development of algorithms and statistical models which actually allow computers to learn and make predictions or make decisions without being explicitly programmed.
Hello my friends,
In this article you will get to know all about ML(machine learning). I have tried to explained all necessary topics about machine learning in very simpler words. I hope you will like it.
Understanding Machine Learning
As it clearly stated above that ML is a subset of AI, that means AI is a bigger picture here.
Machine learning is a field that helps computers to automatically analyze and interpret data, it helps to discover patterns, and improve their performance over time through training.
Now the question arises that where does ML actually stands. See the below picture.

Machine learning (ML) is a subset of artificial intelligence, and deep learning is a subset of machine learning. It clearly says that whatever problems AI is facing that can be handle using ML, and ML issues can be further resolve by DL.
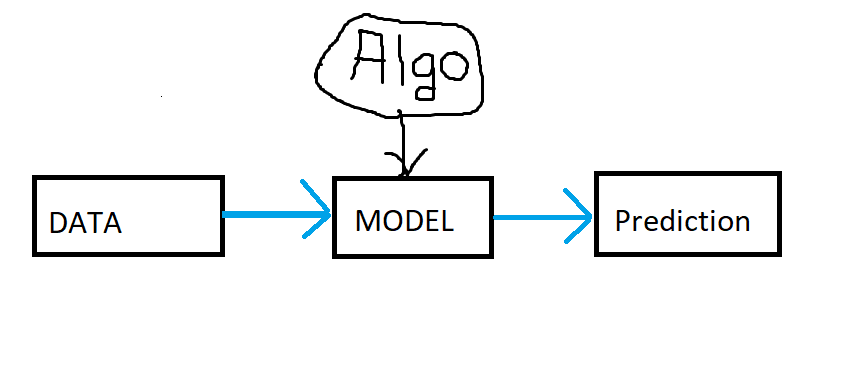
In conventional programming for each problem statement we write separate code to handle it, which is not at all correct for large datasets. Whereas in ML we write our model logic once and predict something for all upcoming data points. ML makes use of little bit of mathematics topics like statistics as well to accurately perform and show results. Now we just have to train the model on given data.
Types of Machine Learning
Mainly there are four types of machine learning. The types can vary if you want to go deep and understand all the sub categories, but here we are going to look at only these four which is mostly used by ML developers.

A – Supervised Learning:
In supervised learning the input and output variables are provided to you already and from that you have to figure out the patterns and relationships between those variables or features or columns. It learns from data and get trained. If you have input and output to train and find patterns in data, then for new data you can use that trained data to find new relations or patterns and predict something.
It has two main categories Regression and Classification.
Regression: If you have input and output both in your dataset, then you can say its supervised and if your output has numerical values, then it is a regression problem. As simple as it is.
Examples are, Predicting house prices, Forecasting stock market prices, Determining the age of a person, etc.
Note: Data mainly has two formats Numerical(e.g. 1,2,3,4) and Categorical(e.g. cat, dog,…).
Classification: If you have input and output both in your dataset, then you can say its supervised and if your output has categorical values, then you can say it is a classification problem.
Examples are, whether prediction, Email spam detection, Sentiment analysis of customer reviews, Classifying handwritten digits in a digit recognition system, etc.
B – Unsupervised Learning:
Unlike supervised learning, in unsupervised learning we only have input variables not output variables. It involves training the algorithm on unlabeled data, where the algorithm discovers patterns or structures in the data without explicit help.
Clustering:
Clustering is a popular technique in unsupervised learning, where the goal is to identify inherent patterns or groupings in a dataset without any predefined labels or target variables. Clustering algorithms aim to partition data points into distinct clusters based on their similarities or proximity in the feature data.
Dimensionality Reduction:
Dimensionality reduction is a technique used in unsupervised learning to reduce the number of features or variables or columns in a dataset while preserving as much relevant information as possible. It aims to address the issue of dimensionality, where because of high-dimensional data it suffer from issues such as increased computational complexity, overfitting, and difficulty in visualizing the data.
Anomaly Detection:

Here the goal is to identify rare or abnormal instances in a dataset.
Association Rule Learning:
Association Rule Learning, also known as Association Rule Mining, is a method used to discover interesting relationships or associations among items or variables in large datasets. It is commonly used in retail, e-commerce, and market analysis to uncover insights that can be utilized for various purposes.
C – Semi-supervised Learning:
Semi-supervised learning is a machine learning approach that lies between supervised learning and unsupervised learning. It combines the use of labeled data (data with known outcomes or target labels) and unlabeled data (data without target labels) to train a model.
In semi-supervised learning, the availability of a large amount of unlabeled data can be leveraged to enhance the performance of a model. The model is trained using both the labeled and unlabeled data. The objective is to learn a representation or decision boundary that aligns with the labeled data while also taking advantage of the information present in the unlabeled data.
D – Reinforcement Learning:
It is inspired by how humans and animals learn from trial and error and adapt their behavior based on feedback. There is no input data provided, you learn it then make mistakes and take feedback and learn again. If model hit right target it will get rewarded.
Batch (offline) vs Online ML
1 – Batch (Offline) Learning:
In batch learning the model is trained using a fixed dataset that dataset contains all available data before the training process begins. The entire dataset is loaded into local memory, and the model learns from this data in one go.
It allows for more computationally efficient training as the model processes the entire data in one pass. The model can be completely optimized over the entire dataset, which can lead to better and more accurate results. Its disadvantage is that it requires sufficient memory to load entire dataset, making it difficult for large datasets that do not fit into memory.
2 – Online Learning (Incremental Learning):
Unlike batch learning, in online learning the model is updated continuously and incrementally as new data becomes available to the model. Instead of using a fixed dataset, the model learns from one data point or a small batch of data points at a time.
It is well-suited for scenarios with continuous streams of data or when data is generated sequentially over time. The difference between these two types are clear right.
Challenges in ML
Machine learning (ML) faces several challenges that researchers and developers continually strive to address. Here are some of the challenges in ML:
- Data Accumulation
- Insufficient Data
- Non-representative Data
- Poor Quality Data
- Irrelevant Features
- Overfitting
- Underfitting
Applications of ML
- Retail (Amazon, Big bazar)
- Banking and Finance
- Transport
- Manufacturing
- Consumer Internet
MLDLC
Machine Learning Development Life Cycle (MLDLC).
This is a iterative process of building, deploying, and maintaining machine learning models.

It’s important to note that the ML development life cycle is iterative and non-linear, often involving feedback loops and multiple iterations to enhance our model’s performance.
Conclusion
Through the use of algorithms, models, and training data ML enables systems to learn from examples and then improve their performance over time. This was my whole understanding of machine learning. I hope you must have learn something today.
FAQ
Q: What is machine learning?
Ans: Machine learning is a subset of artificial intelligence that tells us about the development of algorithms and statistical models which actually allow computers to learn and make predictions or make decisions without being explicitly programmed.
Q: What is the difference between supervised and unsupervised learning?
Ans: Supervised learning uses labeled data, where the input features are paired with corresponding target labels. The model learns to map inputs to outputs based on these labeled examples. Unsupervised learning, on the other hand, works with unlabeled data and aims to discover patterns, relationships, or clusters within the data without any predefined labels.
Q: What are some popular machine learning algorithms?
Ans: There are numerous machine learning algorithms, including linear regression, logistic regression, decision trees, random forests, support vector machines, k-nearest neighbors, k-means clustering, and deep learning algorithms like neural networks.
Q: How can I get started with machine learning?
Ans: To get started with machine learning, you can begin by learning the fundamentals of programming and mathematics, specifically statistics. Familiarize yourself with popular machine learning libraries such as scikit-learn or TensorFlow, and practice more. Good Luck!