
Neural networks are at the heart of many modern technologies, from voice assistants to image recognition systems. But did you know that not all neural networks are created equal? In fact, there are several types of neural networks, each with its own unique structure and function. In this article, we’ll explore some of the most common types of neural networks and their applications, all explained in simple terms.
Overview
There are a lot of neural networks in deep learning, covering each once of them would be difficult. We will look at top 5 neural networks that are widely used in todays industries. These neural networks has very vast concepts and topics, understanding them all is again very overwhelming for beginners. I will try to make it easy for you to understand, so lets begin.
Feedforward Neural Networks
Feedforward neural networks are the simplest type of neural network. They consist of layers of neurons, where each neuron is connected to every neuron in the subsequent layer. These networks process information in a single direction, from input to output, without any loops or cycles. Feedforward neural networks are commonly used for tasks like classification and regression.
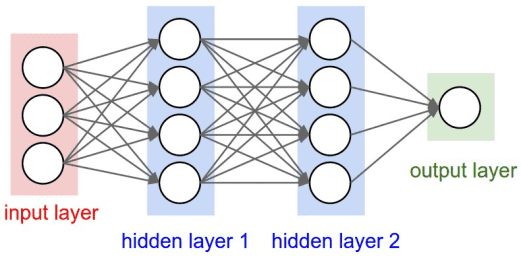
Some common subtypes are:
- MLP (Multi-layer Perceptron)
- Single-layer Perceptron
The MLPs are a subset of feedforward neural networks, which in turn are a subset of artificial neural networks ANNs.
Convolutional Neural Networks (CNNs)
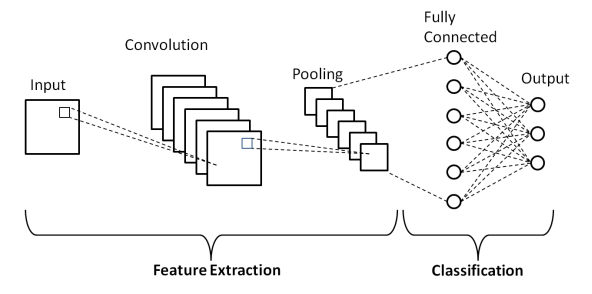
Convolutional neural networks, or CNNs for short, are specifically designed for tasks involving images. They are characterized by their ability to automatically learn hierarchical patterns and features from images. CNNs consist of convolutional layers, pooling layers, and fully connected layers. They excel at tasks like image classification, object detection, and image segmentation.
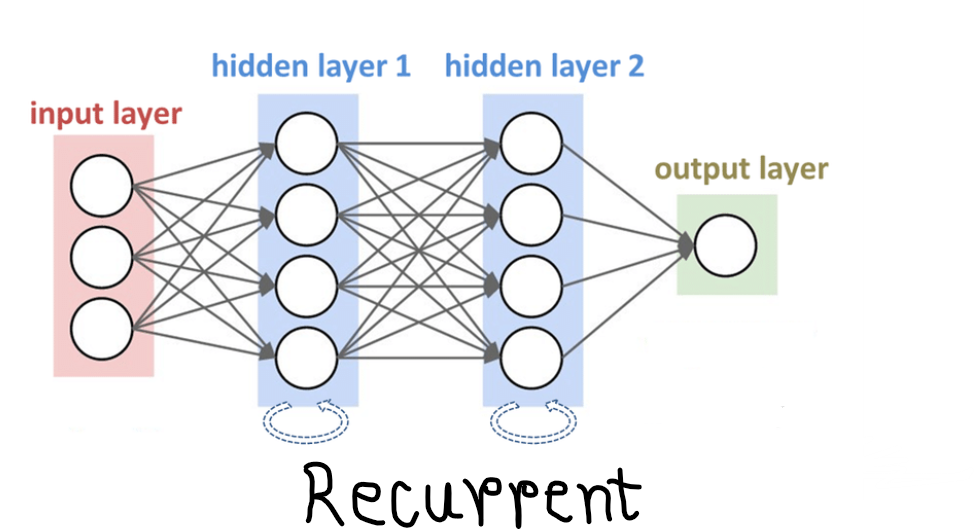
Recurrent Neural Networks (RNNs)
Recurrent neural networks are well-suited for sequential data, such as time series and natural language. Unlike feedforward neural networks, RNNs have connections that form loops, allowing them to maintain a memory of previous inputs. This enables them to process sequences of data and capture temporal dependencies. RNNs are used in applications like speech recognition, language translation, and sentiment analysis.
There is a variant of recurrent neural networks, and it is called as Long Short-Term Memory Networks (LSTMs). This is particularly effective at capturing long-term dependencies in sequential data. They address the issue of vanishing gradients, which can occur when training traditional RNNs on long sequences. LSTMs achieve this by introducing a memory cell that can store information over long periods of time. They are widely used in tasks like text generation, speech recognition, and handwriting recognition.
Generative Adversarial Networks (GANs)
Generative adversarial networks are a unique type of neural network that consists of two networks: a generator and a discriminator. The generator network generates synthetic data samples, while the discriminator network tries to distinguish between real and synthetic data. Through adversarial training, these networks compete against each other, leading to the generation of highly realistic synthetic data. GANs are used for tasks like image generation, image-to-image translation, and data augmentation.

Autoencoders
Autoencoders are neural networks designed for unsupervised learning tasks, such as dimensionality reduction and data compression. They consist of an encoder network that maps input data to a lower-dimensional representation, and a decoder network that reconstructs the original data from the compressed representation. Autoencoders are used in applications like anomaly detection, image denoising, and feature learning.

Neural networks come in various shapes and sizes, each tailored to handle different types of data and tasks. Whether it’s recognizing objects in images, understanding spoken language, or generating realistic images, there’s a neural network for almost every application in the exciting world of deep learning.
History of Deep Learning
The history of deep learning traces back to the 1940s, with the conceptualization of artificial neural networks inspired by the structure and function of the human brain. Early developments in neural network research led to the creation of perceptrons in the 1950s and the backpropagation algorithm in the 1960s, laying the groundwork for modern deep learning. However, progress was limited by computational constraints and theoretical challenges until the late 20th century. Breakthroughs in the 2000s, such as the development of deep belief networks and convolutional neural networks, fueled a resurgence of interest in deep learning. The availability of large datasets, powerful GPUs, and advances in algorithmic techniques like stochastic gradient descent further accelerated progress. Deep learning achieved significant milestones in the 2010s, demonstrating superior performance in tasks like image recognition, natural language processing, and autonomous driving, leading to its widespread adoption across industries and establishing its status as a cornerstone of artificial intelligence.
I genuinely appreciated what you’ve achieved here. The outline is tasteful, your written content fashionable, yet you appear to have acquired some uneasiness regarding what you wish to present forthwith. Undoubtedly, I’ll return more frequently, similar to I have almost constantly, should you sustain this upswing.