
Let’s jump to this Snowflake project step by step with clear explanations and examples. We’ll simulate a small use case with raw customer data in a CSV file. Cleaning and transforming data in Snowflake primarily leverages its powerful SQL capabilities and features designed for efficient data manipulation. The general approach often follows an ELT (Extract, Load, Transform) pattern, where raw data is loaded into Snowflake first, and then transformations are applied.
Step 1: Create a Staging Table for Raw Data
Assume your raw data has some missing values, invalid data types and many more transformations is needed. Use this Customers dummy data from GitHub.
Create the staging table and file format in Snowflake:
-- create staging table
CREATE OR REPLACE TABLE staging_customers (
cust_id STRING,
full_name STRING,
email STRING,
signup_dt STRING,
age STRING,
status STRING
);-- create a file format
CREATE OR REPLACE FILE FORMAT my_csv_format
TYPE = 'CSV'
FIELD_DELIMITER = ','
SKIP_HEADER = 1
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
TRIM_SPACE = TRUE
EMPTY_FIELD_AS_NULL = TRUE
COMPRESSION = 'AUTO';Load your CSV file into this staging table
You can use Snowflake’s Web UI or SQL script via SnowSQL CLI.
For simplicity, let’s assume you’re using a file stage like @my_stage. So just create one file stage using Web UI like below and upload one Customers.csv file to it.
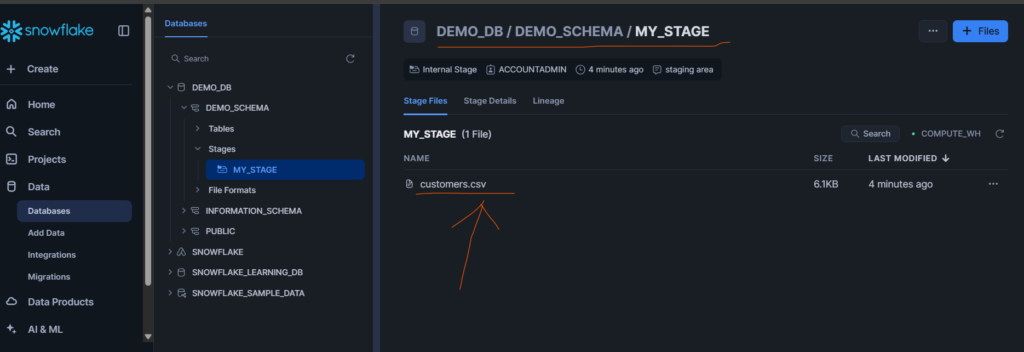
Now from this file stage we need to copy this customers file into staging_customers table.
-- Load your CSV file into this staging table
COPY INTO staging_customers
FROM @"DEMO_DB"."DEMO_SCHEMA"."MY_STAGE"/customers.csv
FILE_FORMAT = my_csv_format;After this we can make sure by querying this staging table like below.
SELECT * FROM staging_customers;Step 2: Create a Cleaned Table
Create the clean final destination table with appropriate data types:
CREATE OR REPLACE TABLE clean_customers (
customer_id INT,
name STRING,
email STRING,
signup_date DATE,
age INT,
is_active BOOLEAN
);Step 3: Transform and Clean the Data with SQL
Now use a INSERT INTO ... SELECT query to clean the data while transferring:
INSERT INTO clean_customers
SELECT
TRY_TO_NUMBER(cust_id) AS customer_id,
INITCAP(full_name) AS name,
LOWER(email) AS email,
TRY_TO_DATE(signup_dt, 'YYYY-MM-DD') AS signup_date,
TRY_TO_NUMBER(age) AS age,
CASE
WHEN LOWER(status) = 'active' THEN TRUE
ELSE FALSE
END AS is_active
FROM staging_customers
WHERE
cust_id IS NOT NULL
AND full_name IS NOT NULL
AND email IS NOT NULL
AND signup_dt IS NOT NULL
AND age IS NOT NULL;Explanation of the transformation:
| Transformation Type | Purpose | SQL Logic |
|---|---|---|
| Rename Columns | Better clarity | Aliases: cust_id AS customer_id |
| Change Data Types | Use correct formats | TRY_TO_NUMBER(), TRY_TO_DATE() |
| Standardize Text | Consistency | INITCAP(), LOWER() |
| Remove Bad Data | Eliminate nulls | WHERE ... IS NOT NULL |
| Logic-Based Column | Flag status | CASE WHEN status='active' THEN TRUE |
Final Verification
Check cleaned data:
SELECT * FROM clean_customers;All of a sudden you’ll see that invalid records are gone and only valid clean data is present. After this let’s perform some additional transformations.
Removing Duplicates:
To remove duplicates in Snowflake using a window function, you can use ROW_NUMBER() to identify duplicate rows and then filter to keep only the first occurrence. It will assigns a rank starting from 1 within each partition.
First Identify Duplicates using SQL like below.
SELECT
cust_id,
full_name,
email,
signup_dt,
age,
status,
ROW_NUMBER() OVER (PARTITION BY cust_id ORDER BY signup_dt DESC) AS row_num
FROM staging_customers;Now Remove Duplicates and Keep the Latest Record, you can use a Common Table Expression (CTE).
WITH ranked AS (
SELECT
cust_id,
full_name,
email,
signup_dt,
age,
status,
ROW_NUMBER() OVER (PARTITION BY cust_id ORDER BY signup_dt DESC) AS row_num
FROM staging_customers
)
SELECT *
FROM ranked
WHERE row_num = 1;Use Aggregate functions to summarize data:
To summarize your staging_customers dataset in Snowflake using aggregate functions, here are some common use cases and SQL examples:
- Count Total Records
SELECT COUNT(*) AS total_records
FROM staging_customers;It shows total number of rows in the table (including duplicates).
- Count Active vs Inactive Customers
SELECT status, COUNT(*) AS total_customers
FROM staging_customers
GROUP BY status;Groups by status (active, inactive, pending, NULL) and counts each.
- Average Age of Customers
SELECT AVG(TRY_TO_NUMBER(age)) AS avg_age
FROM staging_customers;Converts age to numeric and calculates the average.
- Minimum and Maximum Signup Date
SELECT
MIN(TRY_TO_DATE(signup_dt, 'YYYY-MM-DD')) AS earliest_signup,
MAX(TRY_TO_DATE(signup_dt, 'YYYY-MM-DD')) AS latest_signup
FROM staging_customers;It finds the earliest and latest signup dates.
- Number of Customers per Year
SELECT
YEAR(TRY_TO_DATE(signup_dt, 'YYYY-MM-DD')) AS signup_year,
COUNT(*) AS total_customers
FROM staging_customers
WHERE signup_dt IS NOT NULL
GROUP BY signup_year
ORDER BY signup_year;It extracts year from signup_dt and groups customers by year.
- Count of Null Values in Each Column
SELECT
SUM(CASE WHEN cust_id IS NULL THEN 1 ELSE 0 END) AS null_cust_id,
SUM(CASE WHEN full_name IS NULL THEN 1 ELSE 0 END) AS null_full_name,
SUM(CASE WHEN email IS NULL THEN 1 ELSE 0 END) AS null_email,
SUM(CASE WHEN signup_dt IS NULL THEN 1 ELSE 0 END) AS null_signup_dt,
SUM(CASE WHEN age IS NULL THEN 1 ELSE 0 END) AS null_age,
SUM(CASE WHEN status IS NULL THEN 1 ELSE 0 END) AS null_status
FROM staging_customers;Pivoting and Unpivoting Data
Snowflake supports pivoting and unpivoting data for transforming rows into columns and vice versa. Here’s how you can do both on your staging_customers dataset.
Pivoting Data in Snowflake:
Pivoting converts row values into columns. For example, let’s count customers by status for each signup year.
SELECT *
FROM (
SELECT
YEAR(TRY_TO_DATE(signup_dt, 'YYYY-MM-DD')) AS signup_year,
status
FROM staging_customers
WHERE signup_dt IS NOT NULL
)
PIVOT (
COUNT(*) FOR status IN ('active', 'inactive', 'pending')
) AS p;Pivots the status column into separate columns: active, inactive, and pending. Shows counts for each combination.
| SIGNUP_YEAR | ACTIVE | INACTIVE | PENDING |
|---|---|---|---|
| 2021 | 10 | 4 | 2 |
| 2022 | 8 | 3 | 1 |
Unpivoting Data in Snowflake:
Unpivoting converts columns into rows. For example, if we have a pivoted table, we can bring it back to row format. Suppose we have the pivoted result as above (p), now unpivot it:
SELECT signup_year, status, total_count
FROM p
UNPIVOT (
total_count FOR status IN (active, inactive, pending)
) AS u;It converts columns active, inactive, and pending back into rows under the column status.
How to Use Materialized Views
In Snowflake, Views and Materialized Views are powerful tools for managing transformations and improving query performance. Unlike normal view, a Materialized View (MV) stores the results of the query physically, so queries on it are much faster. Snowflake automatically refreshes it when underlying data changes (incremental refresh). Use it when you query the same transformed data repeatedly.
Create a Materialized View
-- Create a Materialized View
CREATE OR REPLACE MATERIALIZED VIEW mv_clean_customers AS
SELECT
TRY_TO_NUMBER(cust_id) AS customer_id,
INITCAP(full_name) AS name,
LOWER(email) AS email,
TRY_TO_DATE(signup_dt, 'YYYY-MM-DD') AS signup_date,
TRY_TO_NUMBER(age) AS age,
CASE
WHEN LOWER(status) = 'active' THEN TRUE ELSE FALSE
END AS is_active
FROM staging_customers;We can querying this Materialize View.
SELECT * FROM mv_clean_customers; -- Precomputed, fasterWhat is a UDF in Snowflake
User-Defined Functions (UDFs) in Snowflake allow you to encapsulate custom logic for data cleaning and transformation, which you can reuse across multiple queries. A UDF is a function you define using SQL or JavaScript that can be called in queries like built-in functions.
- Create a SQL UDF to Clean Status
CREATE OR REPLACE FUNCTION normalize_status(input STRING)
RETURNS STRING
AS
$$
TRIM(LOWER(input))
$$;SELECT normalize_status(status) FROM staging_customers;- Create a SQL UDF to Validate Email
CREATE OR REPLACE FUNCTION is_valid_email(email STRING)
RETURNS BOOLEAN
AS
$$
email ILIKE '%@%.%'
$$;SELECT email, is_valid_email(email) AS valid_email
FROM staging_customers;How to do Performance Monitoring
Snowflake provides QUERY_HISTORY and QUERY_PROFILE to monitor and optimize query performance. These tools help you find slow queries, analyze resource usage, and optimize transformations.
- QUERY_HISTORY: Track Past Queries
SELECT *
FROM TABLE(INFORMATION_SCHEMA.QUERY_HISTORY())
ORDER BY START_TIME DESC
LIMIT 10;- QUERY_PROFILE: Analyze Query Execution Details
QUERY_PROFILE is available in the Snowflake UI (Web Interface) for each query. We can view execution steps (scans, joins, aggregations). Also check data distribution and parallelism.
How to use Snowflake Streams and Tasks
Snowflake Streams and Tasks are essential for incremental processing and automating transformations. They help you build near real-time pipelines without manually running queries.
What is a Snowflake Stream?
A Stream tracks changes (INSERT, UPDATE, DELETE) to a table so you can process only the new or changed rows instead of reprocessing the whole table. It works like Change Data Capture (CDC).
Create a Stream on the Staging Table
CREATE OR REPLACE STREAM staging_customers_stream
ON TABLE staging_customers
SHOW_INITIAL_ROWS = TRUE;SHOW_INITIAL_ROWS = TRUE means existing rows will appear once in the stream as if newly inserted.
Check Stream Data
SELECT * FROM staging_customers_stream;What is a Snowflake Task?
A Task automates SQL statements to run on a schedule or trigger.
- Runs SQL queries or calls stored procedures.
- Can be scheduled (cron) or chained for DAG workflows.
Create a Task to Process Incremental Data
Suppose we want to move new rows from staging to clean_customers using the stream:
CREATE OR REPLACE TASK task_load_clean_customers
WAREHOUSE = compute_wh
SCHEDULE = '5 MINUTE'
AS
INSERT INTO clean_customers
SELECT
TRY_TO_NUMBER(cust_id),
INITCAP(full_name),
LOWER(email),
TRY_TO_DATE(signup_dt, 'YYYY-MM-DD'),
TRY_TO_NUMBER(age),
CASE WHEN LOWER(status) = 'active' THEN TRUE ELSE FALSE END
FROM staging_customers_stream
WHERE METADATA$ACTION = 'INSERT';It Runs every 5 minutes, reads new rows from the stream and cleans and inserts them into clean_customers.
Start the Task
ALTER TASK task_load_clean_customers RESUME;View Task Status
SHOW TASKS;Task runs every 5 min to transform and insert new rows into clean_customers. It requires no manual intervention (automation). So these are the some transformations we can do on our datasets. Let me know if you like this beginners project on snowflake.